# dom操作:增删改查
HTML 与 DOM 有什么不同
<p>是 HTML 元素,但又常常将<p>这样一个元素称为 DOM 节点,那么 HTML 和 DOM 到底有什么不一样呢?
根据 MDN 官方描述:文档对象模型(DOM)是 HTML 和 XML 文档的编程接口。
也就是说,DOM 是用来操作和描述 HTML 文档的接口。如果说浏览器用 HTML 来描述网页的结构并渲染,那么使用 DOM 则可以获取网页的结构并进行操作。一般来说,我们使用 JavaScript 来操作 DOM 接口,从而实现页面的动态变化,以及用户的交互操作。
文档对象模型(DOM)是 HTML 和 XML 文档的编程接口。
+ children chileNodes
+ firstChild&firstElementChild
+ cloneNode
# createElement 创建元素
var div = document.createElement("div");
注意
createElement创建的元素并不属于html文档,它只是创建,并未添加到html,要调用appendChild或insertBefore等方法将其添加到HTML文档树中
# createTextNode 创建文本内容
var textNode = document.createTextNode("一个TextNode");
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
</head>
<body>
<div id="k"></div>
</body>
</html>
<script type="text/javascript">
var k =document.getElementById("k");
var a =document.createElement("div");
a.setAttribute("id","t1");
a.innerHTML ="hello";
k.appendChild(a)
var b =document.createElement("div");
b.setAttribute("id","t2")
var b1 =document.createTextNode("go")
b.appendChild(b1)
k.insertBefore(b,a)
</script>
//页面显示
go
hello
# cloneNode
<body>
<div id="parent">
我是父元素的文本
<br/>
<span>
我是子元素
</span>
</div>
<button id="btnCopy">复制</button>
<script>
var parent = document.getElementById("parent");
//点击id="btnCopy"点击执行执行函数(函数内是一个元素的拷贝)
document.getElementById("btnCopy").onclick = function(){
var parent2 = parent.cloneNode(true);
parent2.id = "parent2";
document.body.appendChild(parent2);
}
</script>
</body>
提示
- cloneNode用来返回调用方法的节点的一个副本,它接收一个bool参数,表示是否复制子元素。为true,parent的子节点也被复制,如果传入false,则只复制了parent节点。
- cloneNode创建的节点只是游离有html文档外的节点
- 如果复制的元素有id,则其副本同样会包含该id,由于id具有唯一性,所以在复制节点后必须要修改其id 调用接收的bool参数最好传入,如果不传入该参数,不同浏览器对其默认值的处理可能不同
- 除此之外,注意: 如果被复制的节点绑定了事件,则副本也会跟着绑定该事件吗?这里要分情况讨论: 如果是通过addEventListener或者比如onclick进行绑定事件,则副本节点不会绑定该事件(即使id是没修改,也不会触发) 如果是内联方式绑定比如
<div onclick="showParent()"></div>
这样的话,副本节点同样会触发事件
# createDocumentFragment 创建文档碎片
用来创建一个DocumentFragment。DocumentFragment表示一种 轻量级的文档 ,它的作用主要是存储临时的节点用来准备添加到文档中。主要是用于添加大量节点到文档中时会使用到。
创建了100个li节点,依次添加HTML文档中。每次一创建一新元素,然后添加到文档树中,这个过程会造成浏览器的 回流 。所谓回流简单说就是指元素大小和位置会被重新计算,如果添加元素太多,会造成性能问题。
这就可以用createDocumentFragment了,DocumentFragment不是文档树的一部分,它保存在内存中,不会造成回流。
document.getElementById("btnAdd").onclick = function(){
var list = document.getElementById("list");
var fragment = document.createDocumentFragment();
for(var i = 0;i < 100; i++){
var li = document.createElement("li");
li.textContent = i;
fragment.appendChild(li);
}
list.appendChild(fragment);
}
优化后的代码主要是创建了一个fragment,每次生成的li节点先添加到fragment,最后一次性添加到list
创建api总结
- 它们创建的节点只是一个孤立的节点
- 要通过appendChild添加到文档中
- cloneNode要注意如果被复制的节点是否包含子节点以及事件绑定等问题
- 使用createDocumentFragment来解决添加大量节点时的性能问题
# appendChild(追加为子元素)
将指定的节点添加到调用该方法的节点的子元素的末尾。
parent.appendChild(child);
注意
如果被添加的节点是一个页面中存在的节点,则执行后这个节点将会添加到指定位置,其原本所在的位置将移除该节点,也就是说不会同时存在两个该节点在页面上,相当于把这个节点移动到另一个地方
append方法也可以添加子元素,不过IE浏览器不支持
//可以添加多个子元素,也可以添加文本,而appendChild不行
document.body.append(parent2,"23");
# insertBefore (插入前面)
insertBefore用来添加一个节点到一个参照节点之前
parentNode.insertBefore(newNode,refNode);
- parentNode表示新节点被添加后的父节点
- newNode表示要添加的节点
- refNode表示参照节点,新节点会添加到这个节点之前
- refNode是必传的,如果不传该参数会报错
- 如果refNode是undefined或null,则insertBefore会将节点添加到子元素的末尾
//自己实现一个插入后面元素的方法
function insertAfter(newNode, referenceNode) {
referenceNode.parentNode.insertBefore(newNode, referenceNode.nextSibling);
}
# removeChild (删除子元素)
let oldChild = node.removeChild(child);
//OR
element.removeChild(child);
- child 是要移除的那个子节点.
- node 是child的父节点.
- oldChild保存对删除的子节点的引用. oldChild === child.
解析
- 被移除的这个子节点仍然存在于内存中,只是没有添加到当前文档的DOM树中,因此,你还可以把这个节点重新添加回文档中,当然,实现要用另外一个变量比如上例中的oldChild来保存这个节点的引用.
- 如果使用上述语法中的第二种方法, 即没有使用 oldChild 来保存对这个节点的引用, 则认为被移除的节点已经是无用的, 在短时间内将会被内存管理回收.
- 如果上例中的child节点不是node节点的子节点,则该方法会抛出异常.
// 先定位父节点,然后删除其子节点
var d = document.getElementById("top");
var d_nested = document.getElementById("nested");
var throwawayNode = d.removeChild(d_nested);
// 无须定位父节点,通过parentNode属性直接删除自身
var node = document.getElementById("nested");
if (node.parentNode) {
node.parentNode.removeChild(node);
}
// 移除一个元素节点的所有子节点
var element = document.getElementById("top");
while (element.firstChild) {
element.removeChild(element.firstChild);
}
# replaceChild (替换)
replaceChild用于使用一个节点替换另一个节点
parent.replaceChild(newChild,oldChild);
解析
newChild是替换的节点,可以是新的节点,也可以是页面上的节点,如果是页面上的节点,则其将被转移到新的位置
修改api总结
页面修改型api主要是这四个接口,要注意几个特点:
- 不管是新增还是替换节点,如果新增或替换的节点是原本存在页面上的,则其原来位置的节点将被移除,也就是说同一个节点不能存在于页面的多个位置
- 节点本身绑定的事件会不会消失,会一直保留着
# 获取节点getElement
document.getElementById
document.getElementsByTagName 这个接口根据元素标签名获取元素,返回一个即时的HTMLCollection类型
解析
- 如果没有存在指定的标签,该接口返回的不是null,而是一个空的HTMLCollection
- document.getElementsByName
通过指定的name属性来获取元素,它返回一个即时的NodeList(节点列表)对象。一般用于获取表单元素的name属性
总结
- 返回对象是一个即时的NodeList,它是随时变化的
- 在HTML元素中,并不是所有元素都有name属性,比如div是没有name属性的,但是如果强制设置div的name属性,它也是可以被查找到的
- 在IE中,如果id设置成某个值,然后传入getElementsByName的参数值和id值一样,则这个元素是会被找到的,所以最好不好设置同样的值给id和name
- document.getElementsByClassName
总结
- 返回结果是一个即时的HTMLCollection,会随时根据文档结构变化
- IE9以下浏览器不支持
- 如果要获取2个以上classname,可传入多个classname,每个用空格相隔,例如
var elements = document.getElementsByClassName("test1 test2");
- document.querySelector
如果有多个节点满足匹配条件,则返回第一个匹配的节点。
- document.querySelectorAll
返回的是一个非即时的NodeList,也就是说结果不会随着文档树的变化而变化
# elementFromPoint()
elementFromPoint方法返回位于页面指定位置的元素。
var element = document.elementFromPoint(x, y);
如果坐标值无意义(比如负值),则返回null。
总结
document.getElementById返回一个对象 document.getElementsByName和document.getElementsByClasName返回一个对象数组
# Attribute
# getAttribute()(获取属性)
getAttribute()用于获取元素的attribute值
node.getAttribute('id');
//表示获取node元素的id属性的 ‘值’
# createAttribute()(创建属性)
createAttribute()方法生成一个新的属性对象节点,并返回它。
attribute = document.createAttribute(name);
//createAttribute方法的参数name,是属性的名称。
# setAttribute()(设置属性)
setAttribute()方法用于设置元素属性
var node = document.getElementById("div1");
node.setAttribute("id", "ct");
//name为属性名称 ;value为属性值
等同于
var node = document.getElementById("div1");
var a = document.createAttribute("id");
a.value = "ct";
node.setAttributeNode(a);
# romoveAttribute()(删除属性)
removeAttribute()用于删除元素属性
# element.attributes(将属性生成数组对象)
var attr = element.attributes;
示例
var para = document.getElementsByTagName("p")[0];
//获取该元素属性(多个属性会形成一个数组对象)
var atts = para.attributes;
# hasAttribute()
如果存在指定属性,则 hasAttribute() 方法返回 true,否则返回 false。
document.getElementsByTagName("BUTTON")[0].hasAttribute("onclick");
# hasAttributes()
document.body.hasAttributes()
- 如果指定节点拥有属性,则 hasAttributes() 方法返回 true,否则返回 false。
- 如果指定节点不是元素节点,则返回值始终是 false。
# textContent innerText innerHTML outerHTML
- innerText返回的是元素内包含的文本内容(只返回文本节点类型,且如果是隐藏的或者不渲染的元素里的文本也不返回);
- innerHTML返会元素内HTML结构,包括元素节点、注释节点、文本节点,注意xss攻击防范;
- outerHTML返回包括元素节点自身和里面的所有元素节点、注释节点、文本节点;
- textContent 属性设置或返回指定节点的文本内容,以及它的 所有后代 。
- createTextNode也可以添加纯文本 如果您设置了 textContent 属性,会删除所有子节点,并被替换为包含指定字符串的一个单独的文本节点。不支持IE8及以下
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<ul id="myList"><li id="item1">Coffee</li><li id="item2">Tea</li></ul>
<p id="demo">单击按钮获取列表元素的文本内容</p>
<button onclick="myFunction()">点我</button>
<script>
function myFunction(){
var lst=document.getElementById("myList");
var x=document.getElementById("demo");
x.innerHTML=lst.textContent;
}
</script>
</body>
</html>
//点击结果CoffeeTea
# parentNode
父节点 节点名称(大写)
bottoms.addEventListener('click',function(e){
if(e.target.nodeName=='INPUT'){
let obj=JSON.parse
(e.target.parentNode.parentNode.getElementsByTagName('sub')[0].innerHTML);
if(e.target.checked){
//....
}
}
},true)
# nextSibling firstChid
firstChild,lastChild,nextSibling,previousSibling都会将空格或者换行当做节点处理,但是有代替属性
所以为了准确地找到相应的元素,会用
firstElementChild,
lastElementChild,
nextElementSibling,
previousElementSibling
但IE8等低版本不兼容。IE9火狐谷歌支持。
# firstChild&firstElementChild
firstChild/firstElementChild选择第一个子元素。 区别,firstChild所有浏览器都支持,firstElementChild不支持老浏览器。
同时,firstElementChild只读取 元素节点 。而firstChild在 IE8不读取空白节点,读取文本节点和元素节点以及注释节点 。其他浏览器可以支持空白节点
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<div id="app">32
<div id="k3">
<p class="wei">pppwqe</p>
<p class="wei">pppwqe</p>
<p class="wei">pppwqe</p>
</div>
<div id="k4">
<span>2112</span>
<h3>12e3</h3>
</div>
</div>
<div id="app1"></div>
</body>
</html>
<script language="javascript" type="text/javascript">
var frag =document.createDocumentFragment();
var app= document.getElementById("app");
var child;
while(child = app.firstElementChild){
console.log(child)
frag.appendChild(child)
}
console.log(app);
document.getElementById("app1").appendChild(frag);
</script>
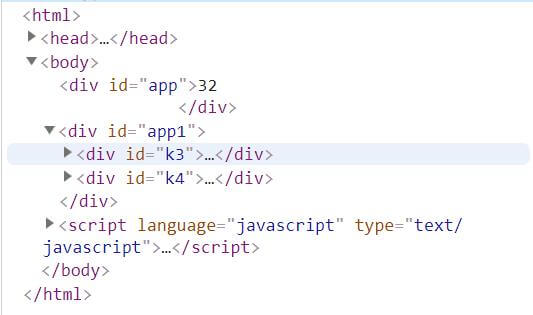
while(child = app.firstChild){
console.log(child)
frag.appendChild(child)
}

二者最后结论不同,正是因为firstElementChild不能去读取像'32'那样的文本节点
# children childNodes
- Node.children:返回指定节点的所有element子节点,即返回节点元素
- Node.childNodes:返回指定节点的所有子节点,包括节点元素和文本元素,
有兼容问题 - hasChildNodes()检测有无子节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Document</title>
<script type="text/javascript">
window.onload=function(){
var oUl=document.getElementById("ul");
var span1=document.getElementById("span1");
var span2=document.getElementById("span2");
var span3=document.getElementById("span3");
var sum=0;
span1.innerHTML=oUl.children.length+"";
span2.innerHTML=oUl.childNodes.length+"";
console.log(oUl.childNodes)
for(var i=0;i<oUl.childNodes.length;i++){
console.log(oUl.childNodes[i])
if(oUl.childNodes[i].nodeType==1){
sum++;
}
}
span3.innerHTML=sum+"";
}
</script>
</head>
<body>
<ul id="ul">
<li>aaa</li>
<li>bbb</li>
ccc
</ul>
children显示的节点数:
<span id="span1"></span>
<br/>
chileNodes显示的节点数:
<span id="span2"></span>
<br/>
nodeType为1的节点数:
<span id="span3"></span>
<br/>
</body>
</html>
各浏览器对比
谷歌 + 火狐 + edge +IE9以上
children显示的节点数: 2
chileNodes显示的节点数: 5
nodeType为1的节点数: 2
--------
//console.log显示
NodeList(5) [text, li, text, li, text]
#text //IE11显示为EmptyTextNode
<li>...</li>
#text //IE11显示为EmptyTextNode
<li>...</li>
"ccc"
IE8
children显示的节点数: 2
chileNodes显示的节点数: 3
nodeType为1的节点数: 2
--------
//console.log显示
[object Object]{0: Object {...}, 1: Object {...}, 2: Object {...}, length: 3}
[object Object]{...innerHTML"aaa"...}
[object Object]{...innerHTML"bbb"...}
[object Object]{....nodeName: "#text", nodeType: 3, nodeValue: "ccc ",...}
其实IE8以下是经过模拟器试验的,并不准确,如chileNodes一会是3一会是2
# innerHTML和creatELement+appendChild
- innerHTML是原生dom方法,速度更快(因为该方法执行编译代码而非解释代码),但是容易XSS攻击,不要在填充数据中使用
- appendChild,js的dom方法来构建js
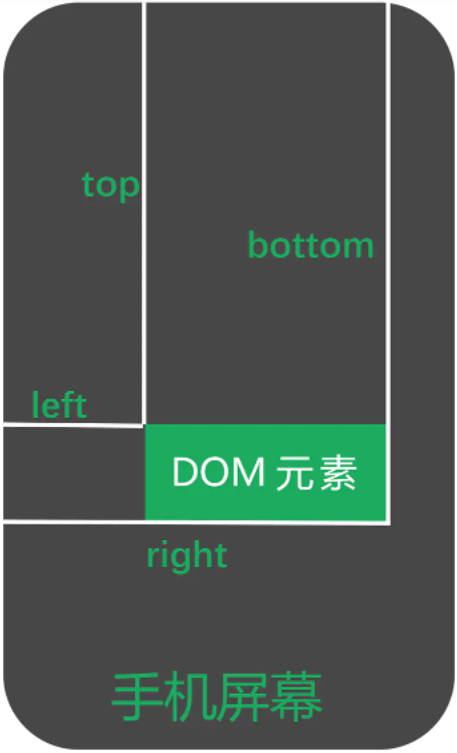
# getBoundingClientRect
Element.getBoundingClientRect() 方法返回元素的大小及其相对于视口的位置。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<title></title>
<style>
*{margin:0;padding:0}
#k1{
width:300px;
height:300px;
border:1px solid red;
margin:100px 0 0 100px;
}
#k2{
width:100px;
height:100px;
border:1px solid blue;
margin-top:50px;
margin-left: 50px;
}
</style>
</head>
<body>
<div id='k1'>
<div id='k2'></div>
</div>
</body>
</html>
<script type="text/javascript">
let elem = document.getElementById('k2');
const offset = ele => {
let result = {
top: 0,
left: 0
}
// 当前为 IE11 以下,直接返回 {top: 0, left: 0}
if (!ele.getClientRects().length) {
return result
}
console.log(ele.getClientRects())
//DOMRectList {0: DOMRect, length: 1}
// 当前 DOM 节点的 display === 'none' 时,直接返回 {top: 0, left: 0}
if (window.getComputedStyle(ele)['display'] === 'none') {
return result
}
result = ele.getBoundingClientRect()
console.log(result)
//DOMRect {x: 151, y: 151, width: 102, height: 102, top: 151,width: 102,x: 151,y: 151}
var docElement = ele.ownerDocument.documentElement
return {
top: result.top + window.pageYOffset - docElement.clientTop,
left: result.left + window.pageXOffset - docElement.clientLeft
}
}
let s= offset(elem)
console.log(s)
</script>
node.ownerDocument.documentElement,ownerDocument 是 DOM 节点的一个属性,它返回当前节点的顶层的 document 对象。ownerDocument 是文档,documentElement是根节点。
# DOMParser
在JavaScript中,DOMParser 对象提供了一种将字符串解析为DOM文档的方法。当你有一个包含HTML内容的字符串,并且想要以编程方式访问或操作这个HTML的DOM结构时,DOMParser 就非常有用。
const parsed = new DOMParser().parseFromString(html, 'text/html');
- new DOMParser():创建一个新的 DOMParser 实例。
- .parseFromString(html, 'text/html'):这是 DOMParser 实例的一个方法,它接受两个参数:
- html:这是一个字符串,包含你想要解析的HTML内容。这个变量应该在你的代码中已经被定义,并且包含了有效的HTML。
- 'text/html':这是一个MIME类型,指定了你想要解析的字符串的内容类型。在这个例子中,我们指定的是 'text/html',表示我们想要解析HTML内容。
- const parsed = ...:这里,我们将 parseFromString 方法返回的结果赋值给一个名为 parsed 的常量。这个结果是一个 Document 对象,它代表了解析后的HTML文档的DOM结构。
const html = '<div><p>Hello, world!</p></div>';
const parsed = new DOMParser().parseFromString(html, 'text/html');
const paragraph = parsed.querySelector('p');
console.log(paragraph.textContent); // 输出: Hello, world!
# 文本复制copy
document.execCommand('copy') 已经在现代浏览器中逐步被废弃,并计划在未来的版本中完全移除。为了替换它,现代浏览器提供了更安全和强大的剪贴板API。
# 使用 Clipboard API 复制文本
Clipboard API 提供了一个更简单和直接的方式来访问剪贴板,并且它是异步的,可以处理更复杂的操作,比如读取和写入不同类型的数据。
// 要复制的文本
const textToCopy = "这是要复制的文本";
// 使用 navigator.clipboard.writeText 进行复制
navigator.clipboard.writeText(textToCopy).then(function() {
console.log('文本复制成功!');
}).catch(function(err) {
console.error('无法复制文本:', err);
});
注意事项
- HTTPS 和用户交互:出于安全考虑,Clipboard API 通常只能在
HTTPS环境下工作,并且通常需要用户交互(如点击事件)才能触发。 - 异步操作:navigator.clipboard.writeText 是一个返回 Promise 的异步函数,这意味着你可以使用 .then() 和 .catch() 来处理成功和失败的情况。
- 浏览器兼容性:虽然大多数现代浏览器都支持 Clipboard API,但总是好的习惯检查浏览器兼容性,并在必要时提供回退方案。
// 假设你有一个图片元素的引用,例如通过 document.getElementById 或其他方式获取
const imgElement = document.getElementById('myImage');
// 创建一个 Blob 对象,表示图片数据
const imgBlob = imgElement.src.startsWith('data:image/')
? dataURItoBlob(imgElement.src) // 如果是 Data URL,则转换为 Blob
: fetch(imgElement.src) // 如果是 URL,则通过 fetch 获取图片数据
.then(response => response.blob());
// 将 Blob 对象转换为 ClipboardItem
const clipboardItem = new ClipboardItem({'image/png': imgBlob});
// 使用 navigator.clipboard.write 复制图片到剪贴板
navigator.clipboard.write([clipboardItem]).then(() => {
console.log('图片复制成功!');
}).catch(err => {
console.error('无法复制图片:', err);
});
// 辅助函数:将 Data URL 转换为 Blob
function dataURItoBlob(dataURI) {
const byteString = atob(dataURI.split(',')[1]);
const mimeString = dataURI.split(',')[0].split(':')[1].split(';')[0];
const ab = new ArrayBuffer(byteString.length);
const ia = new Uint8Array(ab);
for (let i = 0; i < byteString.length; i++) {
ia[i] = byteString.charCodeAt(i);
}
return new Blob([ab], { type: mimeString });
}