# js
- 从编程语言发展历史来说,可以划分为三个阶段:
- 机器语言:1000100111011000,一些机器指令;
- 汇编语言:mov ax一些汇编指令;
- 高级语言:C、C++、js...
但是计算机本身是不认识这些高级语言的,所以代码最终还是需要被转换成机器指令
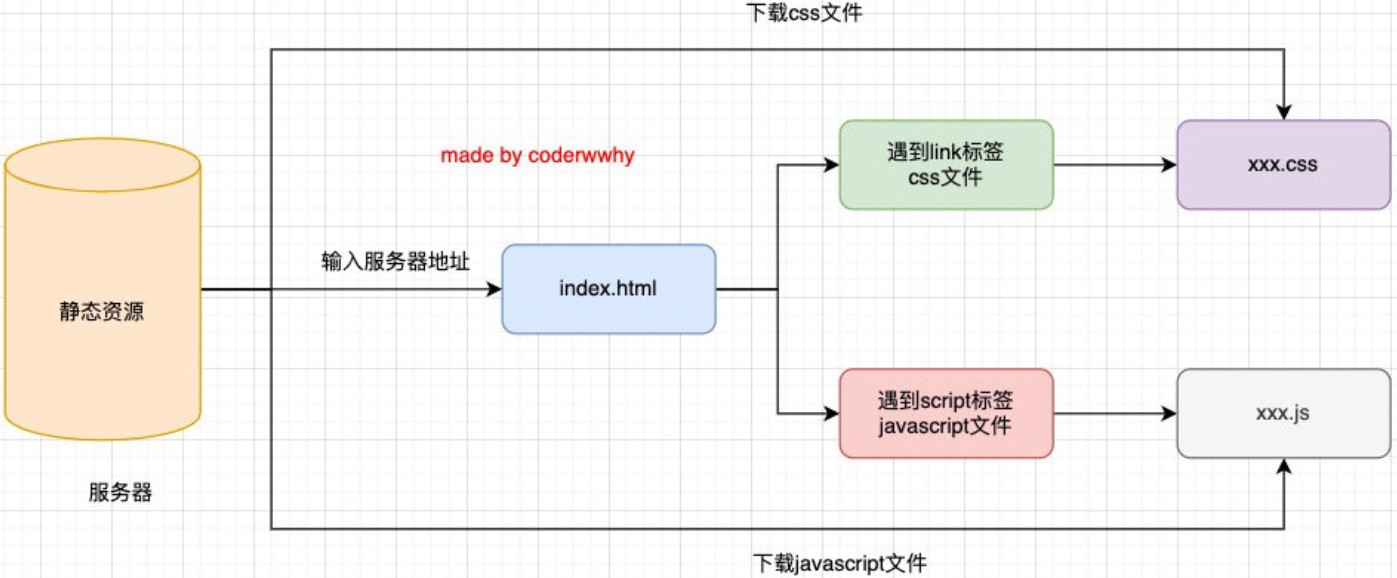
浏览器内核指的是浏览器的排版引擎(layout engine):也称为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或样版引擎
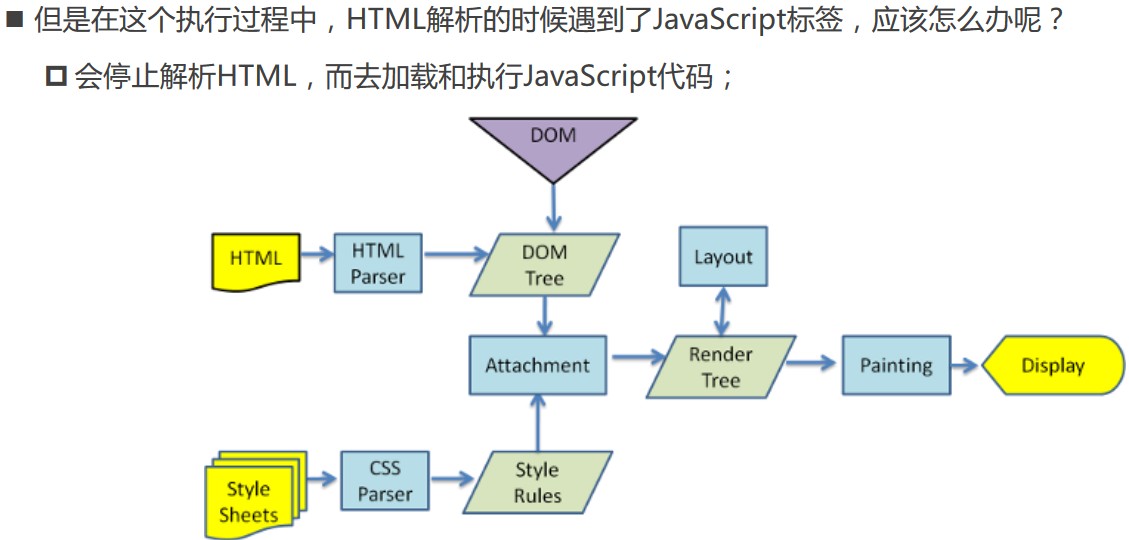
JS代码由谁来执行呢?=> JS引擎
为什么需要JS引擎呢?
- 高级的编程语言都是需要转成最终的机器指令来执行的;
- 事实上编写的JS无论交给浏览器或者Node执行,最后都是需要被
CPU执行的; - 但是CPU只认识自己的指令集,实际上是机器语言,才能被CPU所执行;
- 所以需要JS引擎帮助将JS代码翻译成
CPU指令来执行;
比较常见的JavaScript引擎有哪些呢?
- SpiderMonkey:第一款JS引擎,由Brendan Eich开发(JS作者);
- Chakra:微软开发,用于IE浏览器;
- JavaScriptCore:WebKit中的JS引擎,Apple公司开发;
V8:Google开发的强大JS引擎,帮助Chrome脱颖而出;
浏览器内核:包括渲染部分和js解析部分,比如Trident(IE内核),IE8的JavaScript引擎是Jscript,IE9开始用Chakra;苹果的Webkit引擎包含 WebCore排版引擎及JavaScriptCore解析引擎 ,而谷歌使用的的blink(WebKit中WebCore组件的一个分支)+js引擎则使用的了V8引擎。
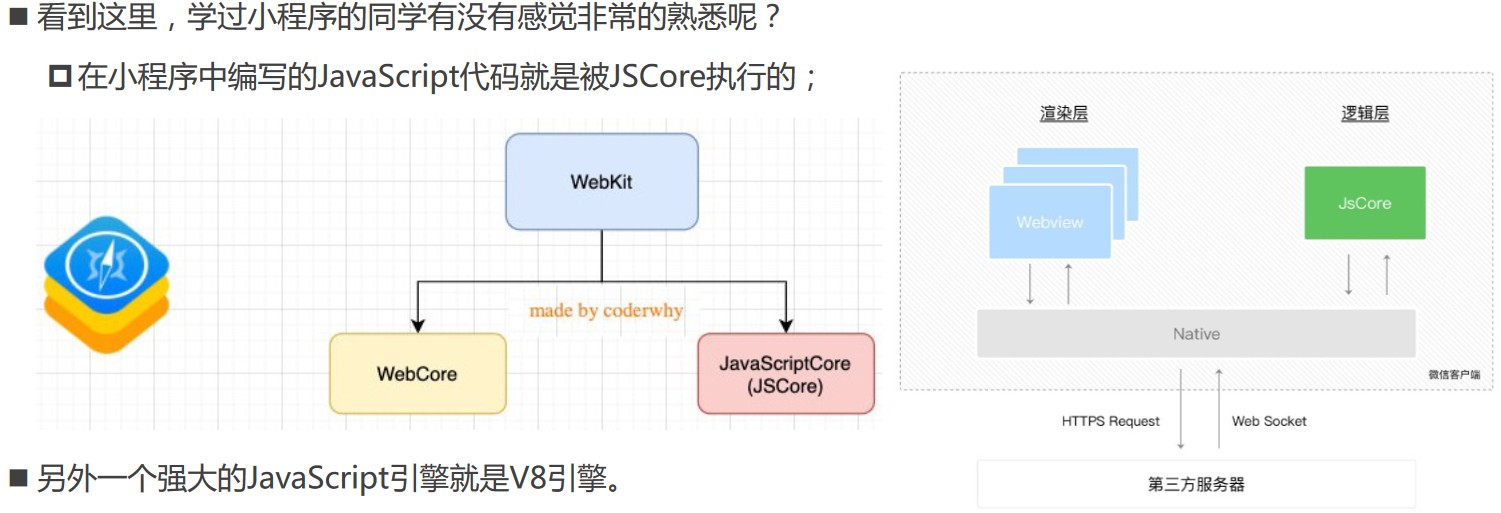
# 浏览器内核和JS引擎的关系
这里先以WebKit为例,WebKit事实上由两部分组成的:
- WebCore:负责HTML解析、布局、渲染等等相关的工作;
- JavaScriptCore:解析、执行JS代码;
JavaScript 是弱类型语言,在运行时才能确定变量类型。即使是如今流行的 TypeScript,也只是增加了编译时(编译成 JavaScript)的类型检测(代码编译过程中编译器会进行词法分析、语法分析、语义分析、生成 AST 等处理)。
同样,JavaScript 引擎在执行 JavaScript 代码时,也会从上到下进行词法分析、语法分析、语义分析等处理,并在代码解析完成后生成 AST(抽象语法树),最终根据 AST 生成 CPU 可以执行的机器码并执行。
这个过程,后面统一描述为语法分析阶段。除了语法分析阶段,JavaScript 引擎在执行代码时还会进行其他的处理。以 V8 引擎为例,在 V8 引擎中 JavaScript 代码的运行过程主要分成三个阶段。
语法分析阶段。 该阶段会对代码进行语法分析,检查是否有语法错误(SyntaxError),如果发现语法错误,会在控制台抛出异常并终止执行。编译阶段。 该阶段会进行执行上下文(Execution Context)的创建,包括创建变量对象、建立作用域链、确定 this 的指向等。每进入一个不同的运行环境时,V8 引擎都会创建一个新的执行上下文。执行阶段。 将编译阶段中创建的执行上下文压入调用栈,并成为正在运行的执行上下文,代码执行结束后,将其弹出调用栈。
其中,语法分析阶段属于编译器通用内容,不再赘述。前面提到的执行环境、词法环境、作用域、执行上下文等内容都是在编译和执行阶段中产生的概念。
# 执行上下文的创建

执行上下文的创建离不开 JavaScript 的运行环境,JavaScript 运行环境包括全局环境、函数环境和eval,其中全局环境和函数环境的创建过程如下:
第一次载入 JavaScript 代码时,首先会创建一个全局环境。全局环境位于最外层,直到应用程序退出后(例如关闭浏览器和网页)才会被销毁。
每个函数都有自己的运行环境,当函数被调用时,则会进入该函数的运行环境。当该环境中的代码被全部执行完毕后,该环境会被销毁。不同的函数运行环境不一样,即使是同一个函数,在被多次调用时也会创建多个不同的函数环境。
在不同的运行环境中,变量和函数可访问的其他数据范围不同,环境的行为(比如创建和销毁)也有所区别。而每进入一个不同的运行环境时,JavaScript 都会创建一个新的执行上下文,该过程包括:
建立作用域链(Scope Chain);
创建变量对象(Variable Object,简称 VO);(在浏览器中,全局环境的变量对象是window对象,因此所有的全局变量和函数都是作为window对象的属性和方法创建的。相应的,在 Node 中全局环境的变量对象则是global对象。)
确定 this 的指向。
由于建立作用域链过程中会涉及变量对象的概念,因此我们先来看看变量对象的创建,再看建立作用域链和确定 this 的指向。
# V8引擎
- V8是用C ++编写的Google开源高性能JavaScript和WebAssembly引擎,它用于Chrome和Node.js等。
- 它实现ECMAScript和WebAssembly,并在Windows 7或更高版本,macOS 10.12+和使用x64,IA-32,ARM或MIPS处理器的Linux系统上运行。
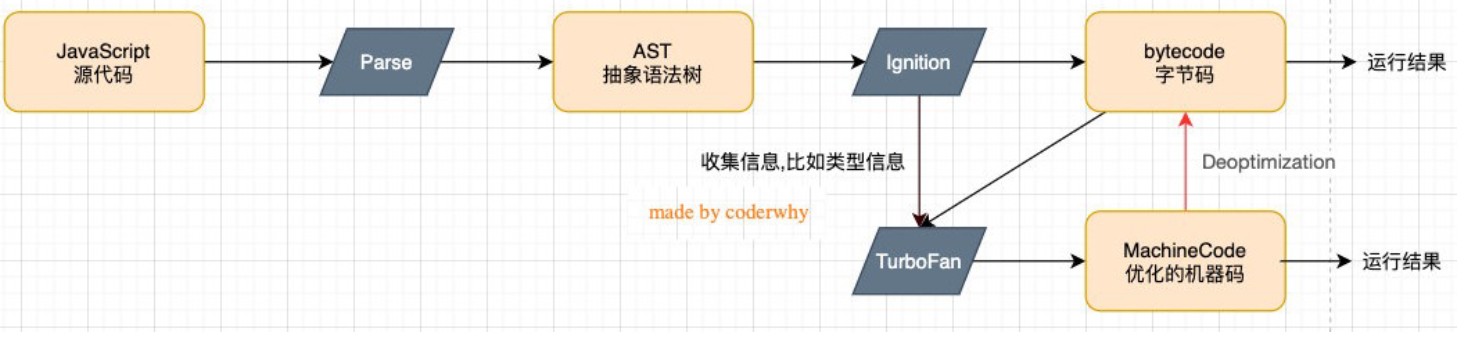
V8引擎本身的源码非常复杂,大概有超过100w行C++代码,可以简单了解一下它执行JS代码的原理:
- Parse模块会将JavaScript代码转换成AST(抽象语法树),因为解释器并不直接认识JS代码;
- 如果函数没有被调用,那么是不会被转换成AST的;
- Parse的V8官方文档:https://v8.dev/blog/scanner
- Ignition是一个解释器,会将AST转换成ByteCode(字节码),可以跨端运行
- 同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算);
- 如果函数只调用一次,Ignition会执行解释执行ByteCode;
- Ignition的V8官方文档:https://v8.dev/blog/ignition-interpreter
TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码;
- 如果一个函数被多次调用,那么就会被标记为
热点函数,那么就会经过TurboFan转换成优化的机器码,提高代码的执行性能; - 但是,机器码实际上也会被还原为ByteCode,这是因为如果后续执行函数的过程中,类型发生了变化(比如sum函数原来执行的是number类型,后来执行变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向的转换成字节码;
- TurboFan的V8官方文档:https://v8.dev/blog/turbofan-jit
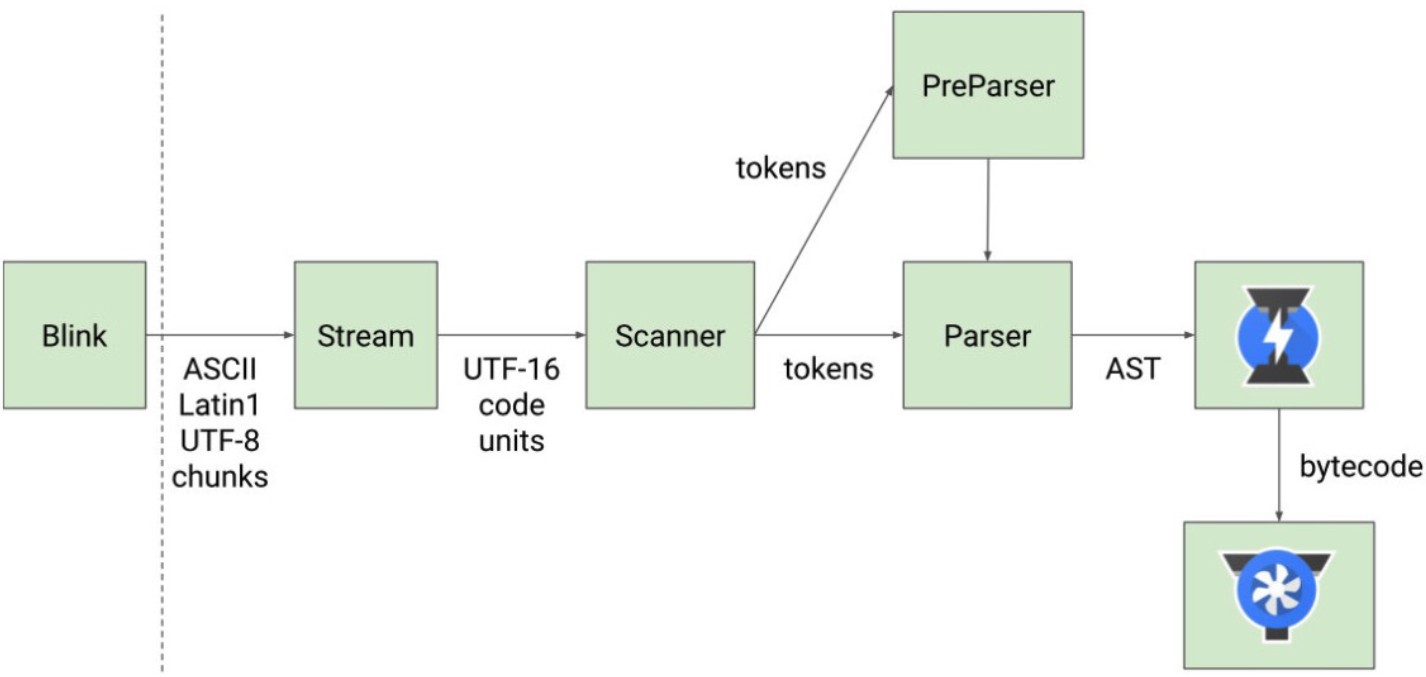
那么JavaScript源码是如何被解析(Parse过程)的呢?
- Blink将源码交给V8引擎,Stream获取到源码并且进行编码转换;
- Scanner会进行词法分析(lexical analysis),词法分析会将代码转换成tokens;
- 接下来tokens会被转换成AST树,经过Parser和PreParser:
- Parser就是直接将tokens转成AST树架构;
- PreParser称之为预解析,为什么需要预解析呢?
- 这是因为并不是所有的JavaScript代码,在一开始时就会被执行。那么对所有的JavaScript代码进行解析,必然会影响网页的运行效率;
- 所以V8引擎就实现了Lazy Parsing(延迟解析)的方案,它的作用是将不必要的函数进行预解析,也就是只解析暂时需要的内容,而对函数的全量解析是在函数被调用时才会进行;
- 比如我们在一个函数outer内部定义了另外一个函数inner,那么inner函数就会进行预解析;
- 生成AST树后,会被Ignition转成字节码(bytecode),之后的过程就是代码的执行过程
- 在编译前会创建一个
globalObject,将代码中的var变量属性值都写入 - 在执行到该行代码就会赋值或者操作,如果提前打印或者使用,也不会报错
- 如果是函数,就会在堆中创建一个存储空间指向对应的globalObject
- 函数执行会创建一个函数执行上下文,也会有一个 AO对象 对应着拿到属性
- 执行时再赋值
- 当函数执行完,函数执行上下文会被弹出栈,AO对象也会被销毁
- 当再次执行函数时,函数执行上下文和AO对象会再次被创建

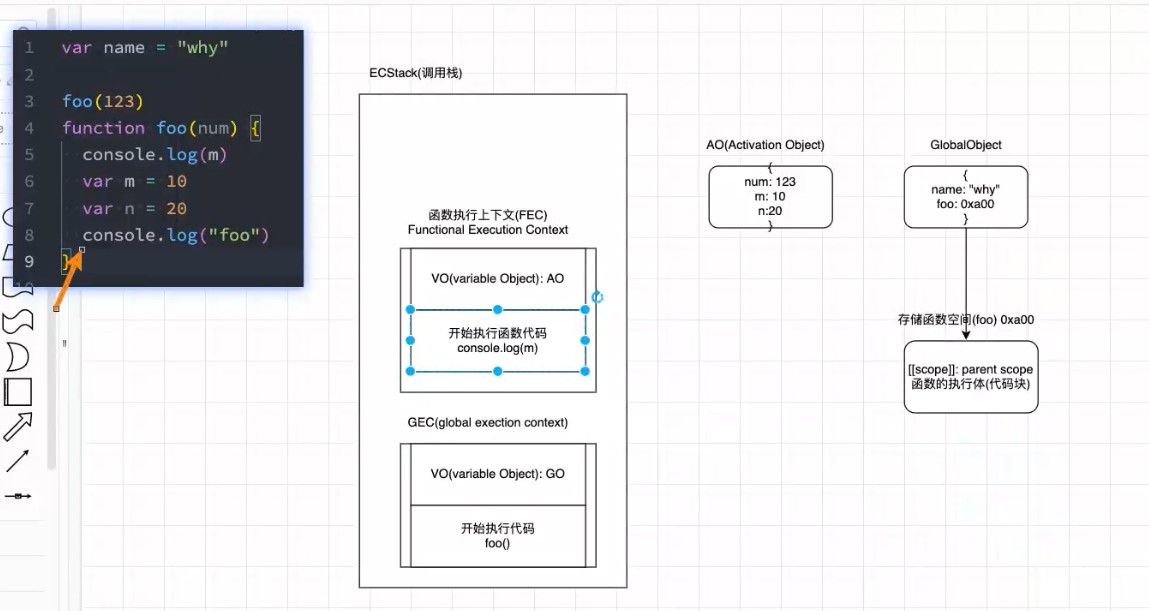
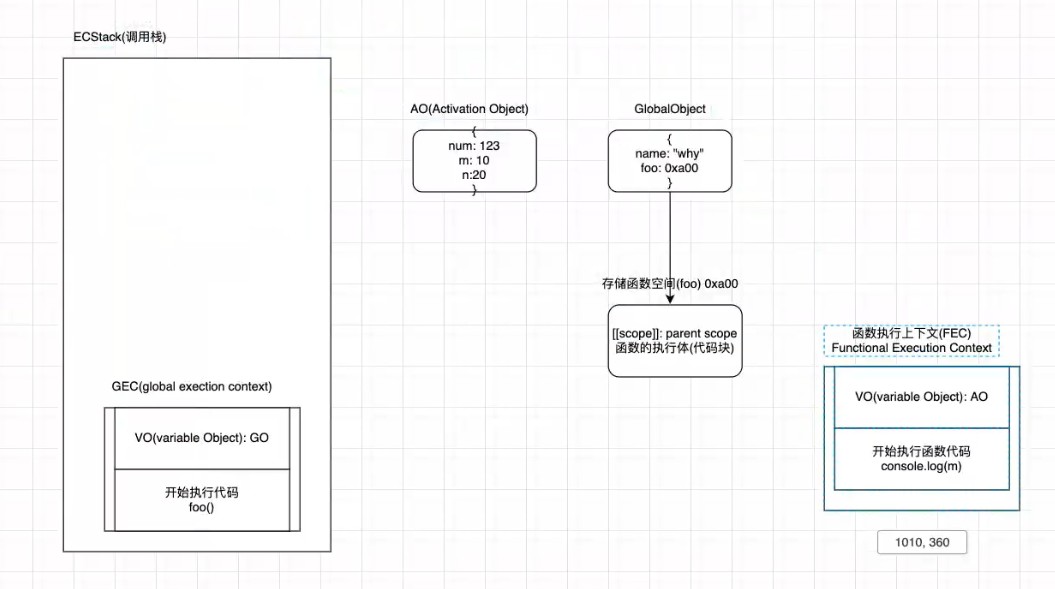
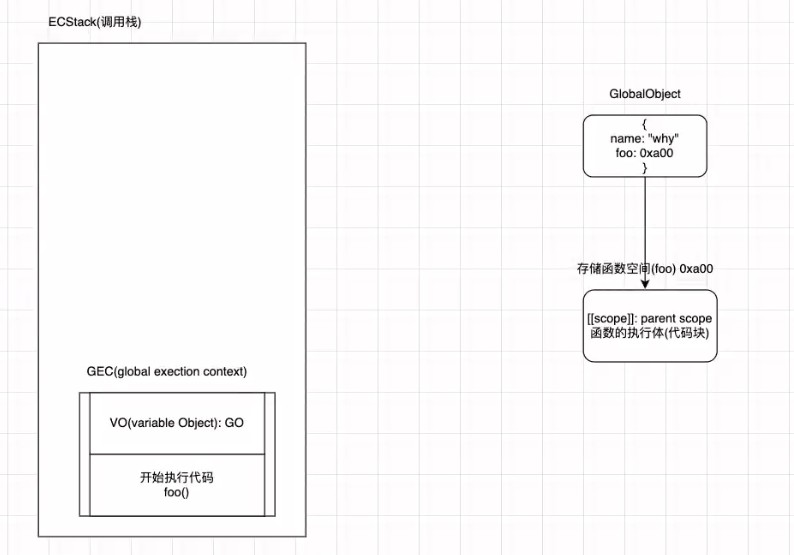
- 作用域链
- scope chain
var name = "why"
foo(123)
function foo(num) {
console.log(m)
var m = 10
var n = 20
function bar() {
console.log(name)
}
bar()
}
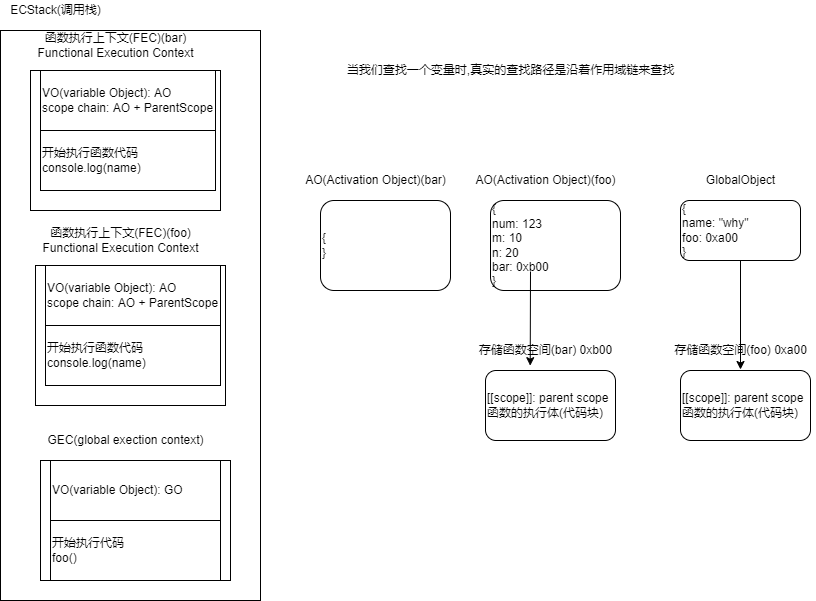
- 函数调用函数
函数foo在创建global object时已经创建在其中,所以他的作用域链指向自己和最外层
var message = "Hello Global"
function foo() {
console.log(message)
}
function bar() {
var message = "Hello Bar"
foo()
}
bar()
// Hello Global
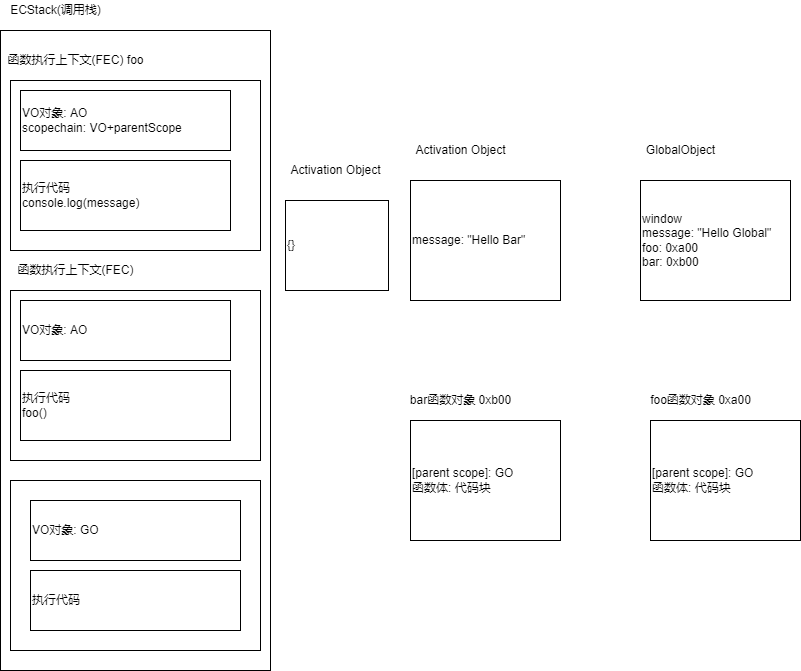

# 关于闭包的特殊情况
A. 没有闭包
var message = 'hello';
function foo(){
var name = 'foo';
var age = 18;
}
function test(){
console.log('test');
}
foo();
test();
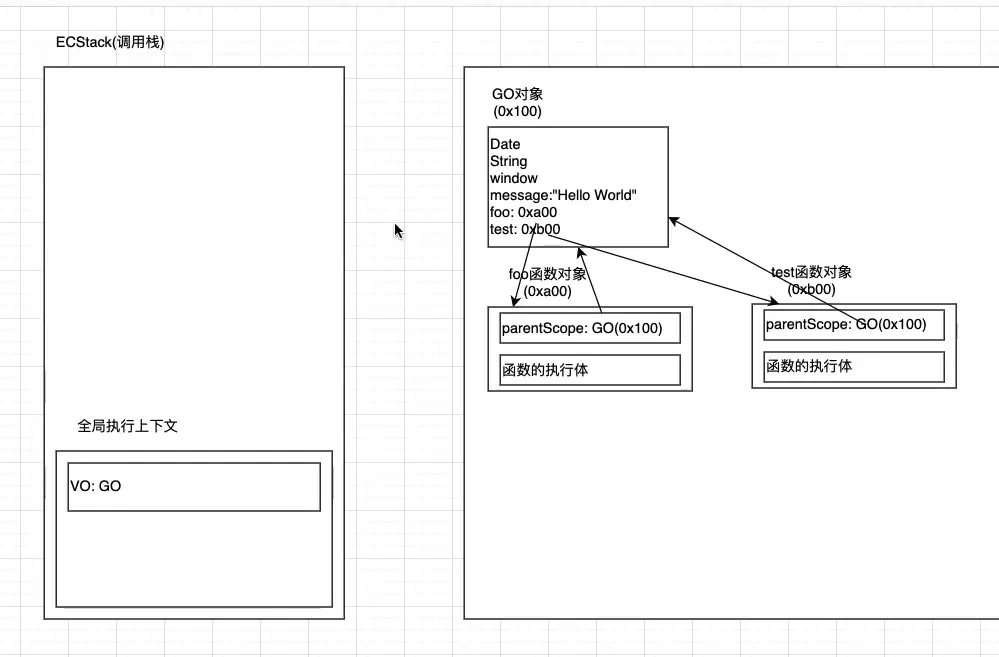
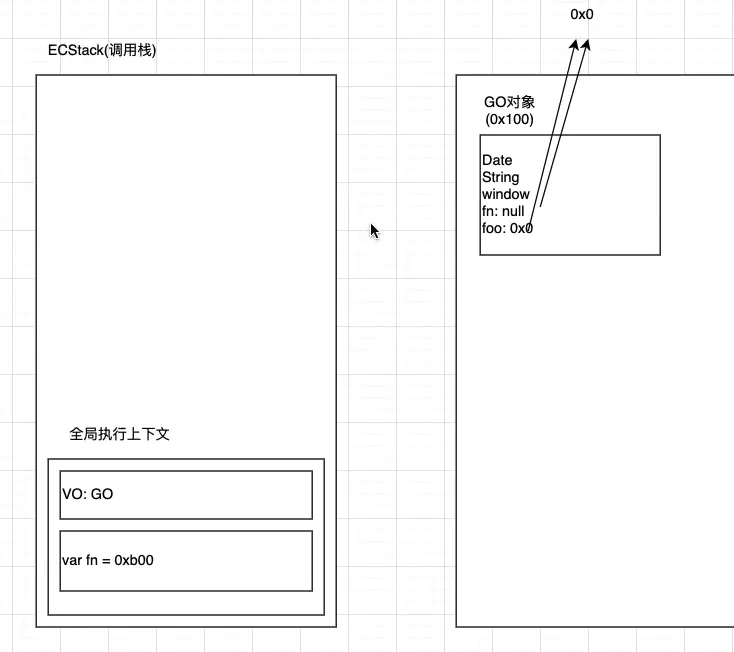
在执行所有代码之前,引擎会在内存里创建GO对象(ox100),它里面有String,window等内置对象。被提前创建好的。然后再去执行代码, GO对象是不会被销毁的
创建执行上下文栈
执行全局代码,然后创建全局执行上下文的VO,这个VO指向GO。
然后,这个时候解析全局代码,往全局GO里面加东西,原来的全局里面有Date,window,String等等,现在又加入message(undefined)foo(oxa00),test(oxboo)等变量。解析foo是函数,就创建一个函数对象 foo(oxa00),里面有函数的父级作用域,也就是全局的GO对象(ox100),还有
函数执行体(函数代码)。 解析test是函数,就创建一个函数对象test(oxb00),里面有函数的父级作用域,也就是全局的GO对象 (ox100),还有函数执行体接下来执行执行代码,先给message赋值,变成了hello,然后执行函数foo。
创建foo函数的函数执行上下文。往里面创建VO对象,VO指向AO对象。 创建一个foo函数的AO对象(ox200)。
默认里面没有对象,然后解析函数,里面放入name:undefined,age:undefined
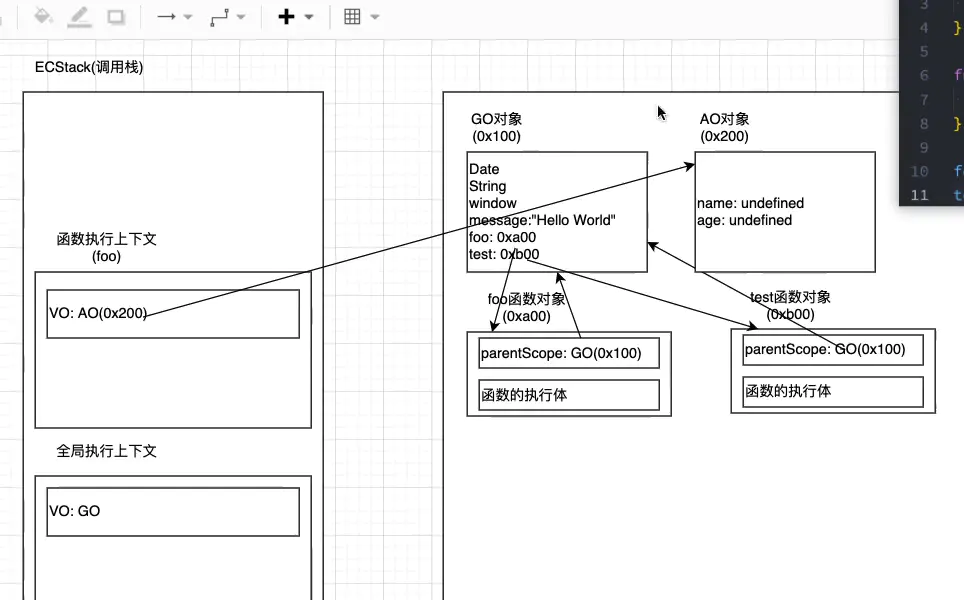
- 然后执行一行一行执行foo里面的代码,同时把AO里面的name赋值'foo',age赋值18;
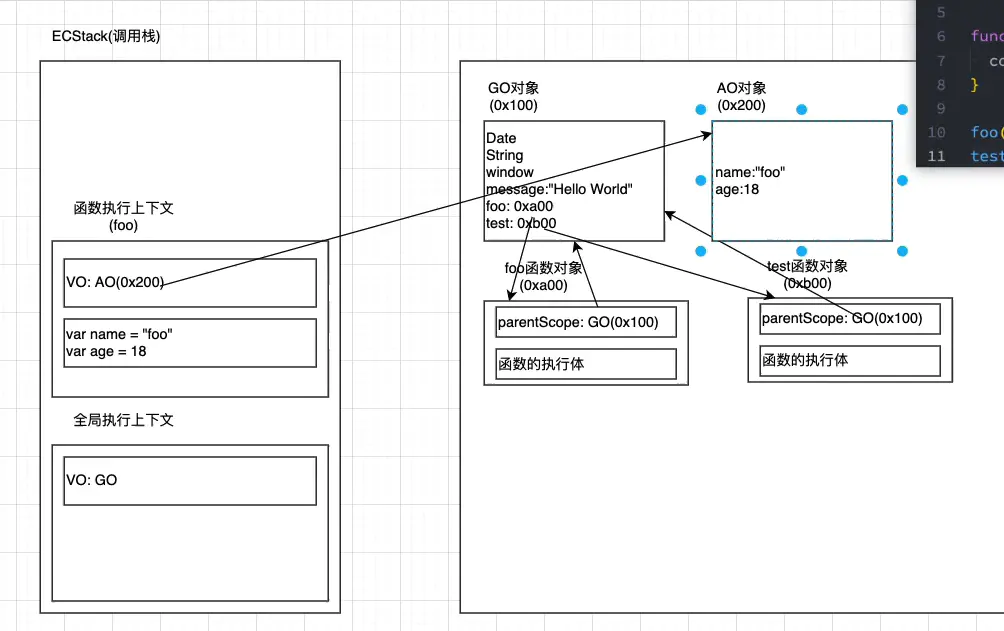
- foo函数执行完之后,栈里面的foo函数执行上下文就会被销毁,一旦销毁,对foo的AO对象的引用将会没有,然后ox2oo就会被销毁。
一般情况下,在函数执行上下文被销毁的同时,函数的AO对象也会被销毁
- test函数执行完之后也是一样,test的AO对象也会被销毁。代码执行完之后的内存结果就是上图。
B. 存在闭包情况
var message = 'hello'
function foo(){
var name = 'foo';
var age = 18;
function bar(){
console.log(name);
console.log(age);
}
return bar
}
var fn = foo();
fn()
执行完var fn = foo();之后
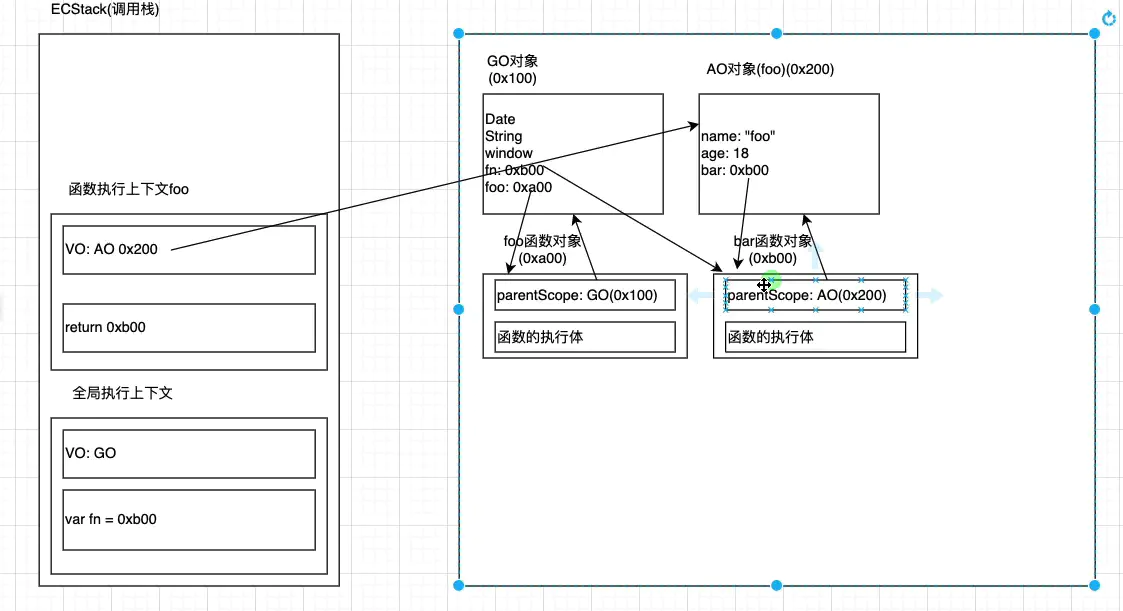
然后foo的执行上下文被销毁,但是bar不会被销毁,因为fn指着它。 然后bar对象不会被销毁,它上面的 foo的ao对象也不会被销毁的。因为bar里面有parentScope这个东西,它指向foo的AO对象。
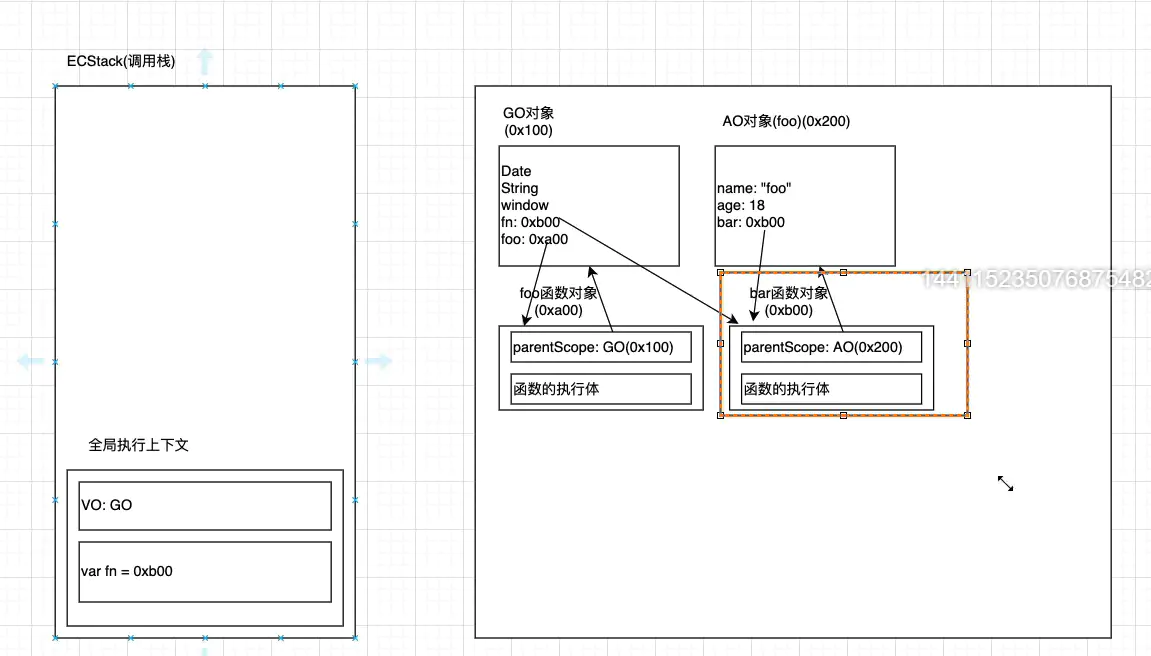
接下来执行fn()
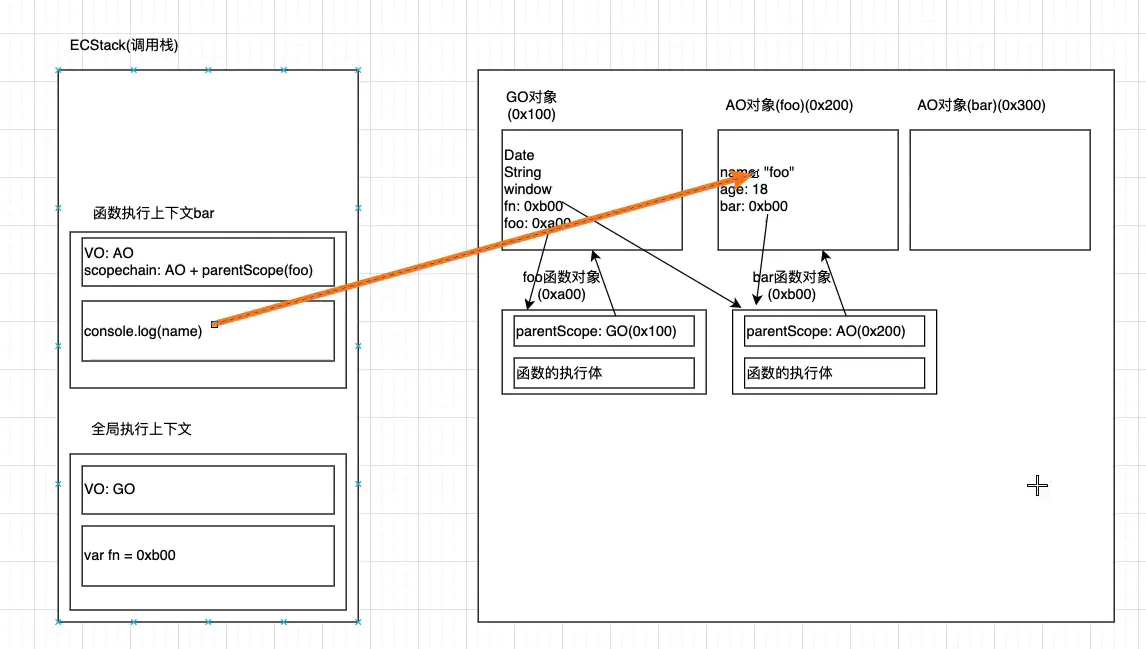
然后销毁fn的执行上下文.
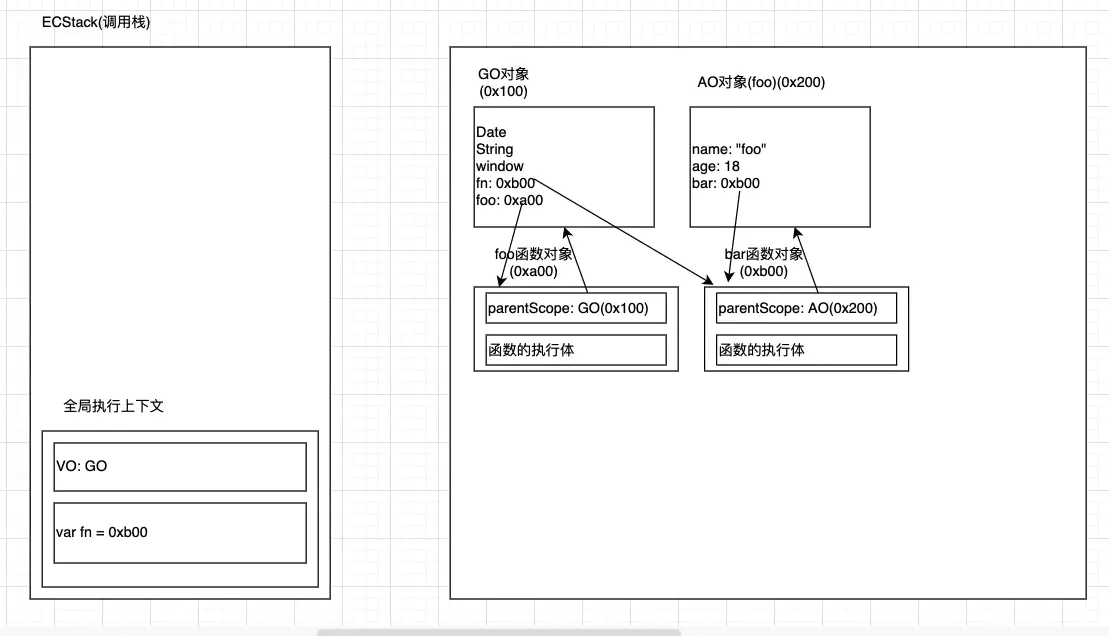
foo的AO对象是没有被销毁的,因为bar的父级作用域是指向foo的AO的。 内存泄漏:这里的bar函数对象一直不会被销毁,也就是foo的AO也一直不会被销毁。 如果执行完一次fn之后,就再也不会执行这个fn了,那么保存的bar和foo的AO也就没有意义了。 该销毁的东西没有被销毁,就是内存泄漏。 fn= null;就可以解决
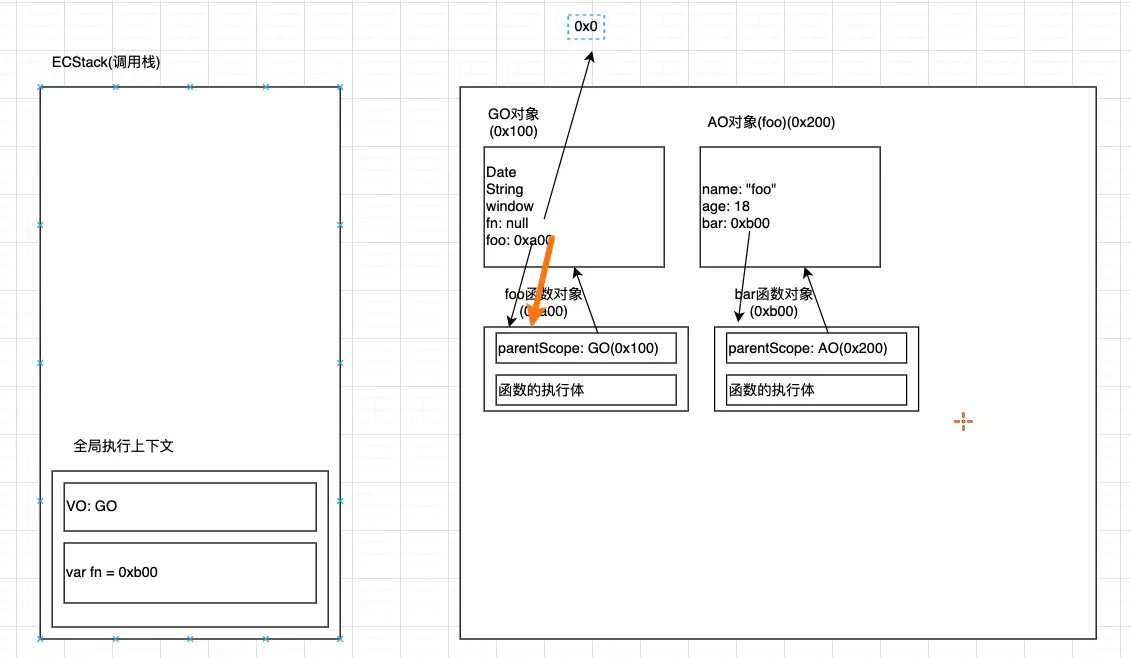
虽然这时候bar和foo的AO循环引用,但是根据标记清除法,只要从根对象GO开始能找到的对象就不会被销毁。
但是bar和foo的AO从根对象指不向他们,他们就会被销毁。
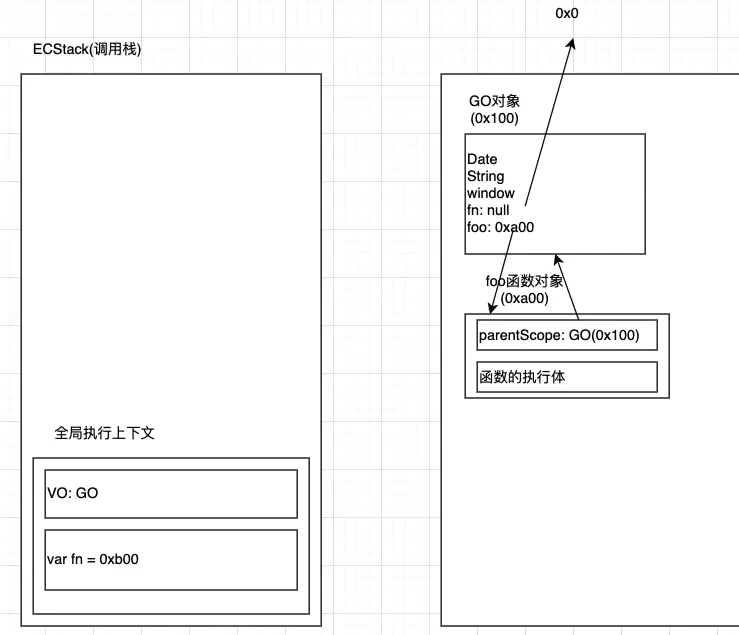
如果也想销毁掉foo这个函数,也是一样,直接foo = null;就可以了;
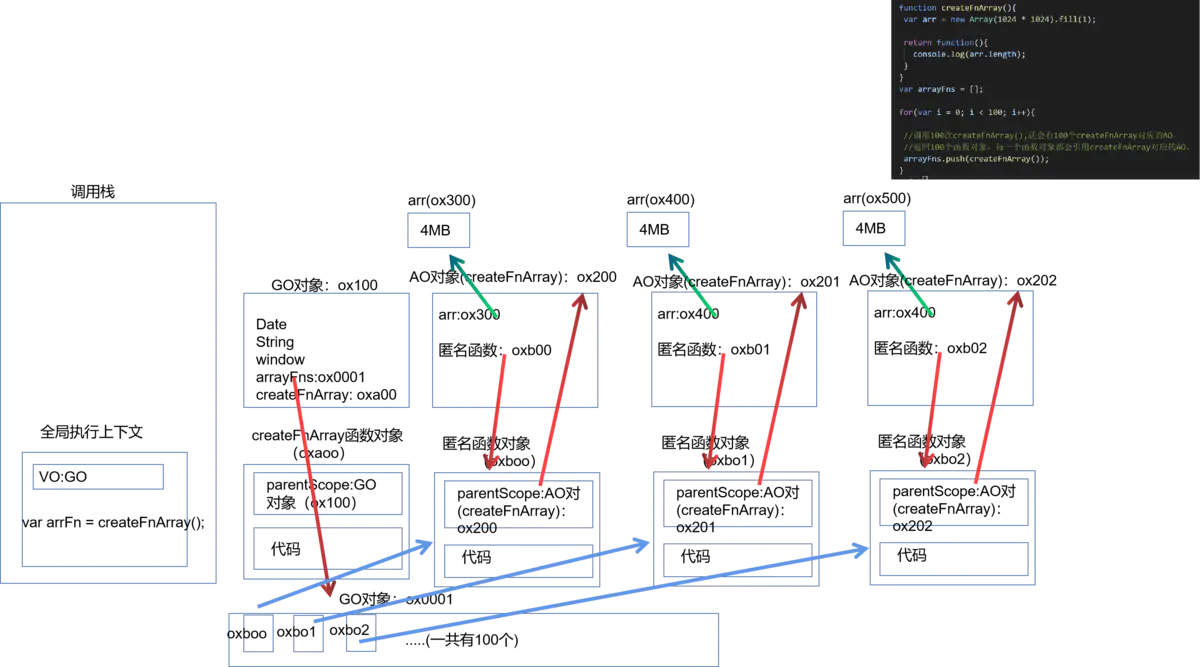
# 内存泄漏场景
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
<script>
// var arr = new Array(1024 * 1024).fill(1)
// console.log(arr);
//整数占据四个字节 4Byte 1MB=1024KB
//1024*1024*4 = 1024 * 1Kb * 4B = 4kB * 1024 = 4MB
//现在这个数组占据的空间是4MB
function createFnArray(){
var arr = new Array(1024 * 1024).fill(1);
return function(){
console.log(arr.length);
}
}
var arrayFns = [];
for(var i = 0; i < 100; i++){
//调用100次createFnArray(),就会有100个createFnArray对应的AO。
//返回100个函数对象,每一个函数对象都会引用createFnArray对应的AO。
arrayFns.push(createFnArray());
}
</script>
</html>
# 作用域相关题
- 虽然return之后代码在执行时不会执行,但是在创建时已经把函数中的a添加到AO对象之中,所以获取的是foo函数中自己的a,初始值undefined
var a = 100
function foo() {
console.log(a)
return
var a = 200
}
foo()//undefined
- 当在函数中声明的变量没有用var声明,那么自动默认是全局对象中声明的
function foo() {
var a = b = 10
// => 转成下面的两行代码
// var a = 10
// b = 10
}
foo()
// console.log(a)//报错
console.log(b) //10
当访问一个变量时,解释器会先在当前作用域查找标识符,如果没有找到就去父作用域找,作用域链顶端是全局对象window,如果window都没有这个变量则报错。
当在对象上访问某属性时,首选会查找当前对象,如果没有就顺着原型链往上找,原型链顶端是null,如果全程都没找到则返一个undefined,而不是报错。
# 栈和数组
栈和数组有什么区别? 没有区别 不是一个概念的东西,
栈逻辑结构。理论模型,不管如何实现,不受任何语言的限制
数组物理结构,真实的功能实现,受限于编程语言
前端实用工具 (opens new window)