# node常见api
# http模块
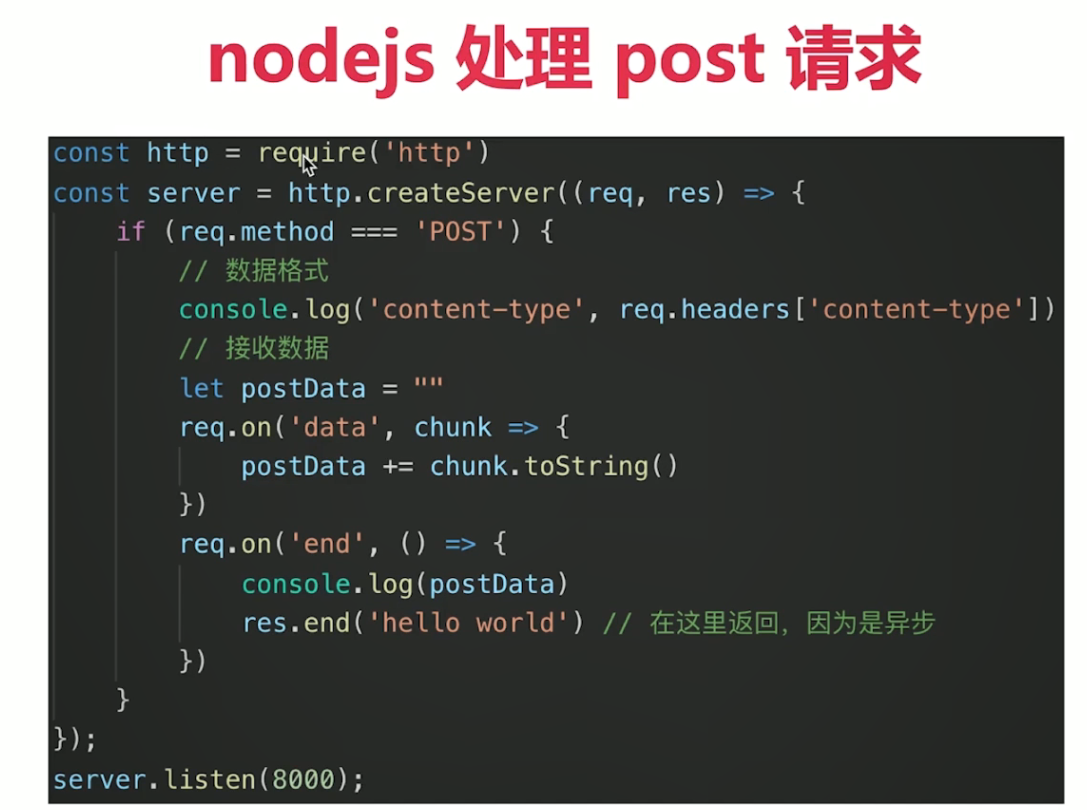
const http = require('http')
const server=http.createServer((req,res)=>{
})
server.listen(8000)
# req res
| req | - |
|---|---|
| req.url | 请求地址 |
| req.method | 请求方法 |
| req.on | 对数据进行处理 |
| req.headers | 请求头 |
req.headers[' content-type']
res.writeHead(404,{" Content-type ":"text/plain "})
res.setHeader(' Content-type','application/json')
| res | 作用 | 语法 |
|---|---|---|
| res.end | 结束时返回内容(返回的是字符串) | res.end("2019") |
| res.setHeader | 设置请求头 | res.setHeader('Content-type','application/json') res.setHeader(' Set-Cookie ',`a=${xxx}`) |
| res.writeHead | 请求头设置和返回内容 | res.writeHead(404,{"Content-type":"text/plain"}) |
# fs和path和_dirname
var path = require("path") //引入node的path模块
console.log(path.resolve('/foo/bar', './baz') )
console.log(path.resolve('/foo/bar', 'baz') )
console.log(path.resolve('/foo/bar', '/baz'))
console.log(path.resolve('/foo/bar', '../baz') )
console.log(path.resolve('home','/foo/bar', '../baz') )
console.log(path.resolve('home','./foo/bar', '../baz') )
console.log(path.resolve('home','foo/bar', '../baz') )
// path.resolve('/foo/bar', './baz') // returns '/foo/bar/baz'
// path.resolve('/foo/bar', 'baz') // returns '/foo/bar/baz'
// path.resolve('/foo/bar', '/baz') // returns '/baz'
// path.resolve('/foo/bar', '../baz') // returns '/foo/baz'
// path.resolve('home','/foo/bar', '../baz') // returns '/foo/baz'
// path.resolve('home','./foo/bar', '../baz') // returns '/home/foo/baz'
// path.resolve('home','foo/bar', '../baz') // returns '/home/foo/baz'
从后向前,若字符以 / 开头,不会拼接到前面的路径(因为拼接到此已经是一个绝对路径);若以 ../ 开头,拼接前面的路径,且不含最后一节路径;若以 ./ 开头 或者没有符号 则拼接前面路径;
+ files
-a.json
-b.json
-c.json
app.json
{
"next":"b.json",
"message":"this is a"
}
{
"next":"c.json",
"message":"this is b"
}
{
"next":null,
"message":"this is c"
}
const fs = require("fs")
const path = require("path")
function getFile(filename,callback){
const fullfilename= path.resolve(__dirname,'files',filename)
fs.readFile(fullfilename,(err,data)=>{
if(err){
console.log(err)
return
}
callback(
JSON.parse(data.toString())
)
})
}
getFile('a.json',aData=>{
console.log(aData);
getFile(aData.next,bData=>{
console.log(bData);
getFile(bData.next,cData=>{
console.log(cData)
})
})
})
/*{ next: 'b.json', message: 'this is a' }
{ next: 'c.json', message: 'this is c' }
{ next: null, message: 'this is c' } */
- fs模块处理文件fs.readFile()
- path 文件路径 path.resolve(__dirname,'files',filename)
const fs = require('fs')
const path = require('path')
const filename = path.resolve(__dirname,'1.txt')
//读取文件
fs.readFile(filename,(err,data)=>{
if(err){
console.error(err)
return
}
console.log(data.toString())
})
//写入文件
const content = '追加内容111111';
const opt={
flag:'w' //追加a 重写w
}
fs.writeFile(filename,content,opt,(err)=>{
if(err){
console.error(err)
return
}
console.log('ok')
})
//判断文件是否存在
fs.exists(filename,(exist)=>{
console.log('exist is',exist)
})
# 流
const fs =require("fs")
let cr = fs.createReadStream("12.txt")
let cw = fs.createWriteStream("100.txt")
cr.pipe(cw)
cw.on("finish",(err,data)=>{
console.log("ok")
})
const http=require('http');
const fs=require('fs');
const zlib=require('zlib');
let server=http.createServer((req, res)=>{
let rs=fs.createReadStream(`www${req.url}`);
//rs.pipe(res);
res.setHeader('content-encoding', 'gzip');
let gz=zlib.createGzip();
rs.pipe(gz).pipe(res);
rs.on('error', err=>{
res.writeHeader(404);
res.write('Not Found');
res.end();
});
});
server.listen(8080);
# querystring 查询字符串
querystring 模块提供用于解析和格式化 URL 查询字符串的实用工具。 它可以使用以下方式访问:
const querystring = require('querystring');
# querystring.decode()
querystring.parse() 的别名
# querystring.encode()
querystring.stringify() 的别名
# querystring.stringify(obj[, sep[, eq[, options]]])
obj <Object> 要序列化为 URL 查询字符串的对象。
sep <string> 用于在查询字符串中分隔键值对的子字符串。默认值: '&'。
eq <string> 用于在查询字符串中分隔键和值的子字符串。默认值: '='。
options
encodeURIComponent <Function> 在查询字符串中将 URL 不安全字符转换为百分比编码时使用的函数。
默认值: querystring.escape()。
# querystring.parse(str[, sep[, eq[, options]]])
将&和=连接的字符串解析成对象格式
# querystring.unescape(str)
querystring.unescape() 方法在给定的 str 上执行 URL 百分比编码字符的解码。
querystring.unescape() 方法由 querystring.parse() 使用,通常不会直接使用它。 它的导出主要是为了允许应用程序代码在必要时通过将 querystring.unescape 分配给替代函数来提供替换的解码实现。
默认情况下, querystring.unescape() 方法将尝试使用 JavaScript 内置的 decodeURIComponent() 方法进行解码。 如果失败,将使用更安全的不会丢失格式错误的 URL 的等价方法。
# querystring.escape(str)
querystring.escape() 方法以对 URL 查询字符串的特定要求进行了优化的方式对给定的 str 执行 URL 百分比编码。
querystring.escape() 方法由 querystring.stringify() 使用,通常不会直接使用。 它的导出主要是为了允许应用程序代码在必要时通过将 querystring.escape 指定给替代函数来提供替换的百分比编码实现。
# response
服务端返回客户端内容
# response.end([data][, encoding][, callback])
data <string> | <Buffer>
encoding <string>
callback <Function>
此方法向服务器发出信号,表明已发送所有响应头和主体,该服务器应该视为此消息已完成。 必须在每个响应上调用此 response.end() 方法。
如果指定了 data,则相当于调用 response.write(data, encoding) 之后再调用 response.end(callback)。
如果指定了 callback,则当响应流完成时将调用它。
# response.setHeader(name, value)
name <string>
value <any>
为隐式响应头设置单个响应头的值。 如果此响应头已存在于待发送的响应头中,则其值将被替换。 在这里可以使用字符串数组来发送具有相同名称的多个响应头。 非字符串值将被原样保存。 因此 response.getHeader() 可能返回非字符串值。 但是非字符串值将转换为字符串以进行网络传输。
response.setHeader('Content-Type', 'text/html');
或:
response.setHeader('Set-Cookie', ['type=ninja', 'language=javascript']);
当使用 response.setHeader() 设置响应头时,它们将与传给 response.writeHead() 的任何响应头合并,其中 response.writeHead() 的响应头优先。
// 返回 content-type = text/plain
const server = http.createServer((req, res) => {
res.setHeader('Content-Type', 'text/html');
res.setHeader('X-Foo', 'bar');
res.writeHead(200, { 'Content-Type': 'text/plain' });
res.end('ok');
});
如果调用了 response.writeHead() 方法并且尚未调用此方法,则它将直接将提供的响应头值写入网络通道而不在内部进行缓存,并且响应头上的 response.getHeader() 将不会产生预期的结果。 如果需要渐进的响应头填充以及将来可能的检索和修改,则使用 response.setHeader() 而不是 response.writeHead()。
# response.writeHead(statusCode[, statusMessage][, headers])
statusCode <number>
statusMessage <string>
headers <Object>
此方法只能在消息上调用一次,并且必须在调用 response.end() 之前调用。
如果在调用此方法之前调用了 response.write() 或 response.end(),则将计算隐式或可变的响应头并调用此函数。
# response.write(chunk[, encoding][, callback])
chunk <string> | <Buffer>
encoding <string> 默认值: 'utf8'。
callback <Function>
# url模块
url 模块用于处理与解析 URL。 url 模块提供了两套 API 来处理 URL:一个是旧版本遗留的 API,一个是实现了 WHATWG标准的新 API。
使用 WHATWG 的 API 解析 URL 字符串:
const myURL =
new URL('https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash');
使用遗留的 API 解析 URL 字符串:
const url = require('url');
const myURL =
url.parse('https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash');
{
protocol: 'https:',
slashes: true,
auth: 'user:pass',
host: 'sub.host.com:8080',
port: '8080',
hostname: 'sub.host.com',
hash: '#hash',
search: '?query=string',
query: 'query=string',
pathname: '/p/a/t/h',
path: '/p/a/t/h?query=string',
href:
'https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash' }
{
href:'https://user:pass@sub.host.com:8080/p/a/t/h?query=string#hash',
origin: 'https://sub.host.com:8080',
protocol: 'https:',
username: 'user',
password: 'pass',
host: 'sub.host.com:8080',
hostname: 'sub.host.com',
port: '8080',
pathname: '/p/a/t/h',
search: '?query=string',
searchParams: URLSearchParams { 'query' => 'string' },
hash: '#hash' }
┌────────────────────────────────────────────────────────────────────────────────────────────┐
│ href │
├──────────┬──┬───────────────────┬───────────────────────┬──────────────────────────┬───────┤
│ protocol │ │ auth │ host │ path │ hash │
│ │ │ ├────────────────┬──────┼─────────┬────────────────┤ │
│ │ │ │ hostname │ port │pathname │ search │ │
│ │ │ │ │ │ ├─┬──────────────┤ │
│ │ │ │ │ │ │ │ query │ │
" https: // user : pass @ sub.example.com : 8080 /p/a/t/h ? query=string #hash"
│ │ │ │ │ hostname │ port │ │ │ │
│ │ │ │ ├────────────────┴──────┤ │ │ │
│ protocol │ │username │ password│ host │ │ │ │
├──────────┴──┼─────────┴─────────┼───────────────────────┤ │ │ │
│ origin │ │ origin │pathname │ search │ hash │
├─────────────┴───────────────────┴───────────────────────┴─────────┴────────────────┴───────┤
│ href │
└────────────────────────────────────────────────────────────────────────────────────────────┘
# util模块
Nodejs 8 有一个新的工具函数 util.promisify()。他将一个接收回调函数参数的函数转换成一个返回Promise的函数。
const repo = 'github:su37josephxia/vue-template'
const desc = '../test'
clone(repo,desc)
async function clone(repo,desc) {
const { promisify } = require('util');
const download = promisify(require('download-git-repo'));
const ora = require('ora');
const process = ora(`火箭下载项目......`);
process.start();
try {
await download(repo, desc);
} catch (error) {
process.fail()
}
process.succeed()
}
# Buffer
// 创建一个长度为10字节以0填充的Buffer
const buf1 = Buffer.alloc(10);
console.log(buf1);
// 创建一个Buffer包含ascii.
// ascii 查询 http://ascii.911cha.com/
const buf2 = Buffer.from('a')
console.log(buf2,buf2.toString())
// 创建Buffer包含UTF-8字节
// UFT-8:一种变长的编码方案,使用 1~6 个字节来存储;
// UFT-32:一种固定长度的编码方案,不管字符编号大小,始终使用 4 个字节来存储;
// UTF-16:介于 UTF-8 和 UTF-32 之间,使用 2 个或者 4 个字节来存储,长度既固定又可变。
const buf3 = Buffer.from('Buffer创建方法');
console.log(buf3);
// 写入Buffer数据
buf1.write('hello');
console.log(buf1);
// 读取Buffer数据
console.log(buf3.toString());
// 合并Buffer
const buf4 = Buffer.concat([buf1, buf3]);
console.log(buf4.toString());
// <Buffer 00 00 00 00 00 00 00 00 00 00>
// <Buffer 61> 'a'
// <Buffer 42 75 66 66 65 72 e5 88 9b e5 bb ba e6 96 b9 e6 b3 95>
// <Buffer 68 65 6c 6c 6f 00 00 00 00 00>
// Buffer创建方法
// hello Buffer创建方法
Buffer类似数组,所以很多数组方法它都有 GBK 转码 iconv-lite